Apache Kafka is written in Scala and Java and is the creation of former LinkedIn data engineers. As early as 2011, the technology was handed over to the open-source community as a highly scalable messaging system. Today, Apache Kafka is part of the Confluent Stream Platform and handles trillions of events every day. Apache Kafka has established itself on the market with many trusted companies waving the Kafka banner.
Data and logs involved in today’s complex systems must be processed, reprocessed, analyzed and handled - often in real-time. And that's why Apache Kafka is playing a significant role in the message streaming landscape. The key design principles of Kafka were formed based on the growing need for high-throughput architectures that are easily scalable and provide the ability to store, process, and reprocess streaming data.
What is Kafka?
At the core, Kafka is a highly scalable and fault tolerant enterprise messaging system.At the top of the diagram, the Producer applications are sending messages to Kafka cluster. The Kafka cluster is nothing but a bunch of brokers running in a group of computers. They take message records from producers and store it in Kafka message log.
At the core, Kafka is a highly scalable and fault tolerant enterprise messaging system.At the top of the diagram, the Producer applications are sending messages to Kafka cluster. The Kafka cluster is nothing but a bunch of brokers running in a group of computers. They take message records from producers and store it in Kafka message log.
Why Kafka?
- Benefits and Use Cases: Kafka is used by over 100,000 organizations across the world and is backed by a thriving community of professional developers, who are constantly advancing the state of the art in stream processing together. Due to Kafka's high throughput, fault tolerance, resilience, and scalability, there are numerous use cases across almost every industry - from banking and fraud detection, to transportation and IoT.
- Data Integration: Kafka can connect to nearly any other data source in traditional enterprise information systems, modern databases, or in the cloud. It forms an efficient point of integration with built-in data connectors, without hiding logic or routing inside brittle, centralized infrastructure.
- Metrics & monitoring: Kafka is often used for monitoring operational data. This involves aggregating statistics from distributed applications to produce centralized feeds with real-time metrics.
- Log aggregation: A modern system is typically a distributed system, and logging data must be centralized from the various components of the system to one place. Kafka often serves as a single source of truth by centralizing data across all sources, regardless of form or volume.
- Stream processing: Performing real-time computations on event streams is a core competency of Kafka. From real-time data processing to dataflow programming, Kafka ingests, stores, and processes streams of data as it's being generated, at any scale.
- Publish-subscribe messaging: As a distributed pub/sub messaging system, Kafka works well as a modernized version of the traditional message broker. Any time a process that generates events must be decoupled from the process or from processes receiving the events, Kafka is a scalable and flexible way to get the job done.
Messaging Systems in Kafka
The main task of managing system is to transfer data from one application to another so that the applications can mainly work on data without worrying about sharing it. Distributed messaging is based on the reliable message queuing process. Messages are queued non-synchronously between the messaging system and client applications.
There are two types of messaging patterns available:
- Point to point messaging system
- Publish-subscribe messaging system
How does Apache Kafka Work?
Kafka allows you to send messages between applications in distributed
systems. The sender can send messages to Kafka, while the recipient gets
messages from the stream published by Kafka.
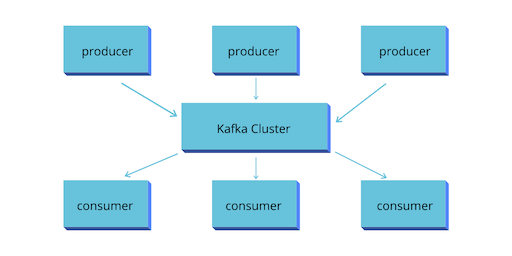
Messages are grouped into topics a primary Kafka’s abstraction. The
sender (producer) sends messages on a specific topic. The recipient
(consumer) receives all messages on a specific topic from many senders.
Any message from a given topic sent by any sender will go to every
recipient who is listening to that topic.
At the bottom of the picture, there are consumer applications. They read
messages from Kafka cluster, processes it and do whatever they want to
do. They may want to send them to Hadoop, Cassandra, HBase or may be
pushing it back again into Kafka for someone else to read these modified
or transformed records.
Kafka Streams
Well, I will say "continuous flow of data." or you can define it as "a constant stream of messages".
Kafka, as a messaging system is so powerful regarding throughput and scalability that it allows you to handle a continuous stream of messages. If you can just plug in some stream processing framework to Kafka, it could be your backbone infrastructure to create a real-time stream processing application. And that is what right side of the diagram is trying to explain. Those are some stream processing applications. They read a continuous stream of data from Kafka, process them and then either store them back in Kafka or send them directly to other systems. Kafka provides some stream processing APIs as well. So you can do a lot of things using Kafka stream processing APIs, or you can use other stream processing frameworks like Spark streaming or Storm.
Kafka Connect
The next thing is Kafka connector. These are the most compelling features. They are ready to use connectors to import data from databases into Kafka or export data from Kafka to databases. These are not just out of the box connectors but also a framework to build specialized connectors for any other application.
Summary
Let us summarize all that we learned in this session.
- Kafka is a distributed streaming platform. You can use it as an enterprise messaging system. That doesn't mean just a traditional messaging system. You can use it to simplify complex data pipelines that are made up of a vast number of consumers and producers.
- You can use it as a stream processing platform. There are two parts of stream processing. Stream and a Processing framework. Kafka gives you a stream, and you can plug in a processing framework.
- Kafka also provides connectors to export and import bulk data from databases and other systems.
We will cover all these things in this training. So, keep watching.
Kafka Components
Kafka Components
Using the following components, Kafka achieves messaging:
1. Kafka Topic
A bunch of messages that belong to a particular category is known as a Topic. Data stores in topics. In addition, we can replicate and partition Topics. Here, replicate refers to copies and partition refers to the division. Also, visualize them as logs wherein, Kafka stores messages. However, this ability to replicate and partitioning topics is one of the factors that enable Kafka’s fault tolerance and scalability.
Kafka Producer
The producers publish the messages on one or more Kafka topics.
Kafka Consumer
Consumers take one or more topics and consume messages that are already published through extracting data from the brokers.
Kafka Broker
These are basically systems which maintain the published data. A single broker can have zero or more partitions per topic.
cd /usr/local/kafka
bin/zookeeper-server-start.sh config/zookeeper.properties
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic testTopic
Created topic "testTopic".
bin/kafka-topics.sh --list --zookeeper localhost:2181
testTopic
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic testTopic
>Welcome to kafka
>This is my first topic
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic testTopic --from-beginning
Welcome to kafka
This is my first topic
https://tecadmin.net/install-apache-kafka-ubuntu/
bin/zookeeper-server-start.sh config/zookeeper.properties
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic testTopic
Created topic "testTopic".
bin/kafka-topics.sh --list --zookeeper localhost:2181
testTopic
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic testTopic
>Welcome to kafka
>This is my first topic
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic testTopic --from-beginning
Welcome to kafka
This is my first topic
https://tecadmin.net/install-apache-kafka-ubuntu/
How does Kafka work in a nutshell?
Kafka is a distributed system consisting of servers and clients that communicate via a high-performance TCP network protocol. It can be deployed on bare-metal hardware, virtual machines, and containers in on-premise as well as cloud environments.
Servers: Kafka is run as a cluster of one or more servers that can span multiple datacenters or cloud regions. Some of these servers form the storage layer, called the brokers. Other servers run Kafka Connect to continuously import and export data as event streams to integrate Kafka with your existing systems such as relational databases as well as other Kafka clusters. To let you implement mission-critical use cases, a Kafka cluster is highly scalable and fault-tolerant: if any of its servers fails, the other servers will take over their work to ensure continuous operations without any data loss.
Clients: They allow you to write distributed applications and microservices that read, write, and process streams of events in parallel, at scale, and in a fault-tolerant manner even in the case of network problems or machine failures. Kafka ships with some such clients included, which are augmented by dozens of clients provided by the Kafka community: clients are available for Java and Scala including the higher-level Kafka Streams library, for Go, Python, C/C++, and many other programming languages as well as REST APIs.
No comments:
Post a Comment